

Derzeit sind Server in den meisten Unternehmen und Organisationen einer der grundlegenden Bestandteile der IT-Infrastruktur. Die Zuverlässigkeit und Verfügbarkeit von Daten, Anwendungen und den Maschinen, auf denen sie laufen, spielen im täglichen Betrieb von Unternehmen eine Schlüsselrolle. Unvorhersehbare Ausfälle dieses Teils der Infrastruktur können zu Unterbrechungen des reibungslosen Funktionierens der Umgebung und anderen unerwünschten Auswirkungen, einschließlich finanzieller oder Imageverluste, führen.
Die beliebteste Lösung, um Ausfällen entgegenzuwirken, sind regelmäßig durchgeführte Backups, die im Artikel auf unserem Blog ausführlich vorgestellt werden. Sie können gespeichert werden:
- lokal – auf einem externen USB-Laufwerk, Magnetbändern oder NAS-Gerät (Network Attached Storage), oft mit zusätzlichem Schutz vor Datenverlust in Form eines RAID-Arrays, das Datenverlust bei einem möglichen Ausfall eines der Laufwerke verhindert
- online – Daten werden auf einem externen Server gespeichert – IaaS-Modell (Infrastructure as a Service), wodurch sie vor lokalen Ausfällen geschützt sind und der Zugriff auf Sicherungskopien unabhängig vom internen Netzwerk des Unternehmens möglich ist.
Was ist DRP? In welchen Fällen wird es benötigt?
Disaster Recovery Plan – Der Disaster Recovery Plan ist ein Dokument, das Verfahren und Verhaltensregeln enthält, deren Einhaltung auf die effiziente Wiederaufnahme des ordnungsgemäßen Betriebs abzielt, unter anderem: IT-Infrastruktur im Falle eines unerwarteten Ausfalls. DRP ist ein Bestandteil der Business Continuity Planning, d. h. einer Strategie zur Sicherstellung der Kontinuität des Betriebs wichtiger Organisationsprozesse.
Der Sanierungsplan wird unter anderem durch die folgenden Indikatoren definiert:
- RPO (Recovery Point Objective) – bestimmt die zulässige Menge an Datenverlust. Dies ist die Zeit zwischen dem Ausfall und der letzten Datensicherung. Unter der Annahme, dass das Unternehmen das RPO-Niveau von 3 Stunden akzeptiert, sollte die Datensicherung bzw. -replikation mindestens alle 3 Stunden erfolgen.
- RTO (Recovery Time Objective) – bestimmt die maximale Zeit, die benötigt wird, um eine Sicherungskopie, Dienste oder Umgebung nach einem Fehler wiederherzustellen.
DRP ist wichtig, wenn das Risiko eines Datenverlusts oder eines fehlenden Zugriffs auf die IT-Infrastruktur hoch ist. Zu den Gefahren, die ein solches Risiko darstellen, gehören:
- Naturkatastrophen – Überschwemmungen, Brände, Erdbeben.
- Technologische Bedrohungen – Unterbrechungen der Medienversorgung, Austritt gefährlicher Stoffe, Ausfälle der IT-Infrastruktur.
- Menschliche Fehler – Datenlecks oder von Menschen verursachte Bedrohungen wie Cyberangriffe.
Durchführung einer Wiederherstellung der Umwelt nach einer Katastrophe – Fallstudie.
In der heutigen technologischen Welt, in der Unternehmen und Organisationen zunehmend auf die IT-Infrastruktur angewiesen sind, ist die Fähigkeit, die Umgebung nach einer Katastrophe effizient wiederherzustellen, ein wesentliches Element zur Aufrechterhaltung der Arbeitseffizienz und Datensicherheit.
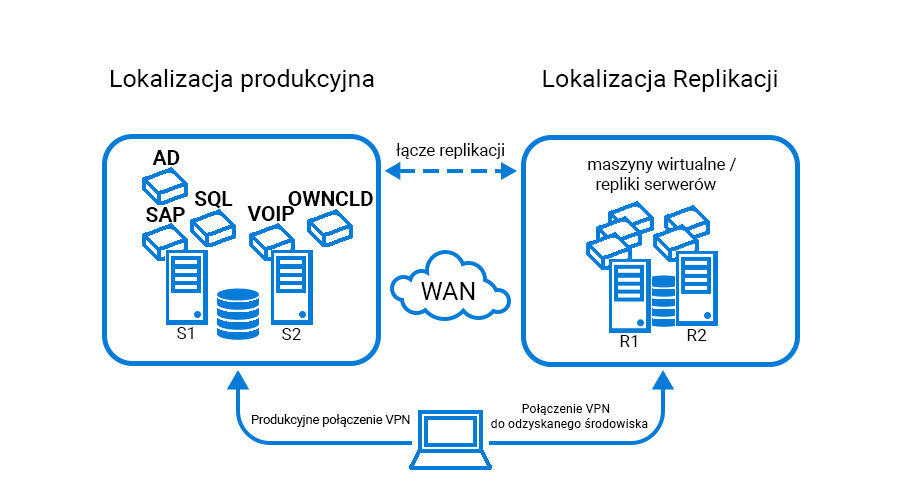
Einer der Kunden von Support Online ist ein Unternehmen, das einen Dienst implementiert hat, der die Wiederherstellung der Umgebung nach einem Ausfall ermöglicht. Der Dienst umfasst die Replikation wichtiger Client-Maschinen, die sich in einem lokalen Serverraum befinden, zu einem geografisch entfernten Rechenzentrum.
Die in diesem Artikel beschriebene Fallstudie beschreibt den Testprozess zur Wiederherstellung der Umgebung nach einem kontrollierten Ausfall der lokalen IT-Infrastruktur.
Umgebungskonfiguration – Schlüsselelemente zur Wiederherstellung
Im Büro des Support Online-Kunden werden zwei wichtige virtuelle lokale VLANs konfiguriert: Eines davon ist die DMZ (demilitarisierte Zone) – ein vom internen Netzwerk getrennter Netzwerkbereich, in dem sich unter anderem Server befinden. Hosten von Websites, die mit größerer Wahrscheinlichkeit von einem Cyberangriff angegriffen werden, wodurch der Angreifer daran gehindert wird, auf das lokale Netzwerk zuzugreifen. Das zweite virtuelle Netzwerk ist das interne Netzwerk, in dem sich die restliche IT-Infrastruktur befindet. Beide Netzwerke müssen auf der Seite der replizierten Umgebung gleich konfiguriert sein, um die Netzwerkkonfiguration im Büro des Kunden widerzuspiegeln.
Server aus dem Büro des Kunden werden in Abständen von einer Stunde auf Support Online-Server repliziert, sodass es im Falle eines Ausfalls im lokalen Serverraum möglich ist, die Umgebung in einem Zustand wiederherzustellen, der mit dem Zustand der Server währenddessen übereinstimmt Reproduzieren.
Ein wichtiges Element ist auch die Konfiguration der VPN-Verbindung, die eine Verbindung zur laufenden Backup-Umgebung ermöglicht. In diesem Fall stellen die Mitarbeiter des Unternehmens über die FortiClient-Anwendung eine Remote-Verbindung über VPN mit dem Büro her. Zu Testzwecken haben wir allen Mitarbeitern automatisch ein zweites Verbindungsprofil zugesandt. Dadurch können sich Remote-Mitarbeiter problemlos mit der Backup-Umgebung verbinden und auf den dort laufenden Servern arbeiten.
Die oben genannte Umgebung, bestehend aus zehn Servern und einer Netzwerkkonfiguration, wird für uns von entscheidender Bedeutung sein, um sie nach einem unerwarteten Ausfall wiederherzustellen.
Der im Artikel beschriebene Test simuliert ein Ereignis, bei dem alle Server im Büro beschädigt wurden, beispielsweise bei einem Serverraumbrand.
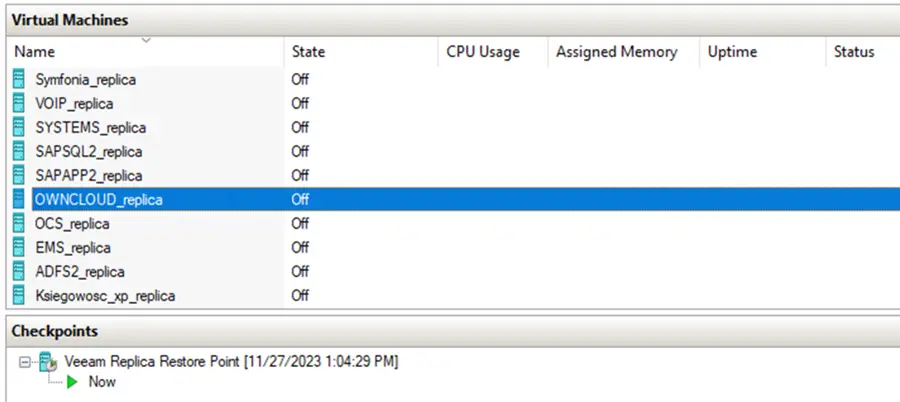
Prozess der Wiederherstellung der Umgebung nach einem Fehler.
Empfangen von Informationen und Diagnostizieren von Fehlern
Der erste Schritt vor der Wiederherstellung ist die Information über einen unerwarteten Ausfall der IT-Infrastruktur. Eine Unterbrechung des Betriebs oder Zugriffs auf Server wird als erstes durch die Online-Support-Überwachung gemeldet, die in einem separaten Artikel zu diesem Thema auf unserem Blog ausführlich vorgestellt wird. Unsere rund um die Uhr im Einsatz befindlichen Ingenieure bestätigen das Auftreten eines Fehlers mit der Person, die auf Kundenseite für die Genehmigung solcher Meldungen verantwortlich ist. Sobald alle an den Verfahren Beteiligten darüber informiert wurden, dass die DRP- und/oder BCP-Verfahren begonnen haben, können wir mit der Wiederherstellung der DR-Umgebung fortfahren.
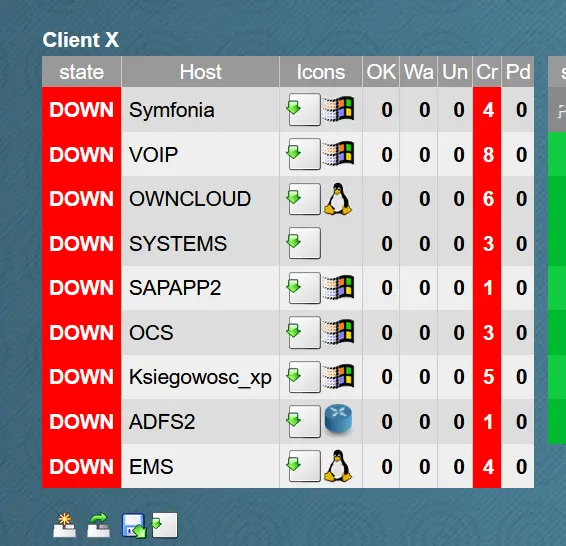
Stoppen der Serverreplikation
Das Deaktivieren oder Stoppen der Replikation in Ihrer Backup-Software ist der nächste Schritt und wichtig für eine reibungslose Testwiederherstellung Ihrer Umgebung. Dadurch können wir nach dem Test zum ursprünglichen Zustand zurückkehren.
Schaffung eines zusätzlichen Maschinenkontrollpunkts
Das Erstellen eines zusätzlichen Wiederherstellungspunkts ist eine zusätzliche Option zur Sicherung der Umgebung. Wenn wichtige Daten in der wiederhergestellten Umgebung gelöscht werden oder verloren gehen, können sie durch Wiederherstellen des Prüfpunkts wiederhergestellt werden.
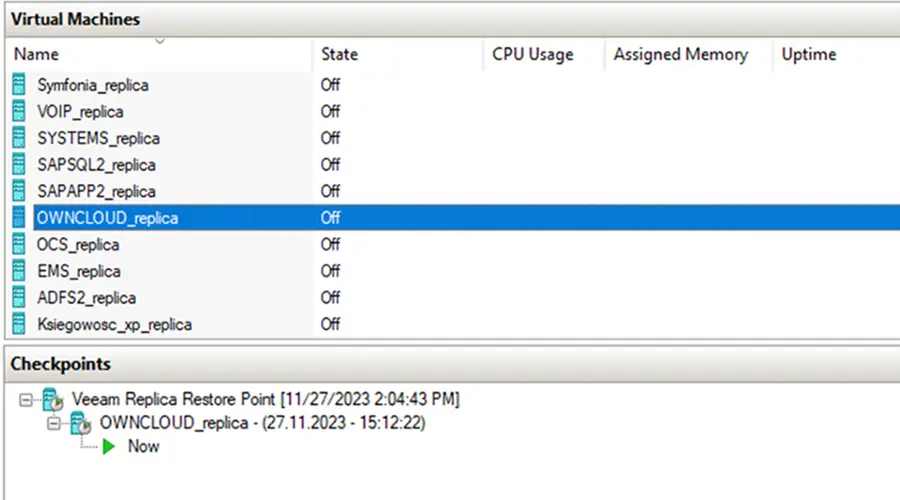
Virtuelle Netzwerkkarten ändern
Das Netzwerk wird neu konfiguriert, nachdem die Replikation deaktiviert wurde. Alle replizierten Server innerhalb der Hyper-V-Virtualisierungssoftware werden dem entsprechenden virtuellen lokalen Netzwerk zugewiesen und die NICs der Maschinen werden geändert, um die Infrastrukturumgebung des Unternehmens vor dem Ausfall zu replizieren. Dadurch werden die Maschinen in den entsprechenden und zugewiesenen VLANs gestartet und die der Welt zugänglichen Dienste bleiben denselben Bedingungen ausgesetzt wie in der Produktionsumgebung (alle Änderungen müssen auf der DNS-Serverseite vorgenommen werden, unter Berücksichtigung neuer/ verschiedene WAN-Adressen).
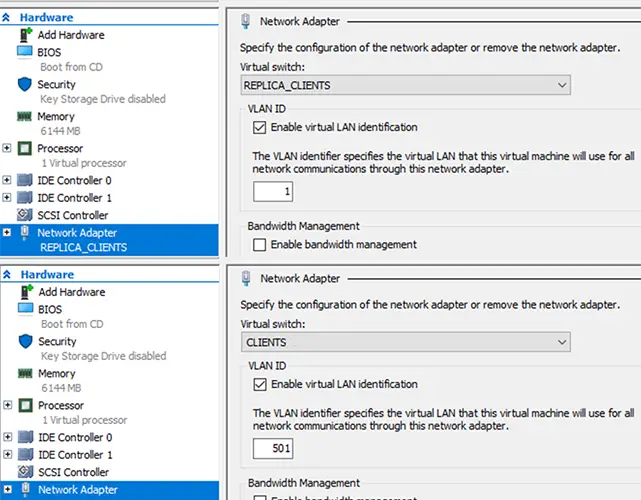
Unten: geänderte Netzwerkkarte und VLAN-Set
Einschalten der Server
Das Einschalten der Maschinen und die Überprüfung des ordnungsgemäßen Betriebs ist der nächste Schritt zur Wiederherstellung der Umwelt. Dabei werden die installierte Software, die Funktionalität der Anwendungskommunikation zwischen Servern, Datenbanken und auf Servern gehostete Websites überprüft.
Beim Starten von Servern ist die Reihenfolge wichtig, in der die Maschinen gestartet werden. Wenn einer der Rechner als DHCP-Server fungiert, sollte dieser zuerst gestartet werden, da sonst die Server, die zugewiesene IP-Adressen erhalten sollen, ihre Netzwerkkonfiguration ändern können, was eine manuelle Konfiguration erforderlich macht.
Jeder Mitarbeiter kann sich über ein Backup-VPN-Profil auf seinem Computer mit der Backup-Umgebung verbinden und auf den dort bereitgestellten Ressourcen arbeiten.
Informationen zur Umweltsanierung
Der letzte Schritt besteht darin, die an DRP-Verfahren beteiligten Personen über die Wiederherstellung und Überprüfung des ordnungsgemäßen Funktionierens der Umgebung zu informieren. Der oben beschriebene DRP-Verfahrenstest ermöglichte es dem Unternehmen, 30 Minuten nach einem Ausfall im lokalen Serverraum weiterzuarbeiten.
Zusammenfassung:
DRP ist ein Schlüsselelement, das bei der Erstellung eines Kontinuitäts-Geschäftsplanungsplans berücksichtigt werden sollte, um den reibungslosen Betrieb des Unternehmens aufrechtzuerhalten und die Zeit der Inaktivität nach einem unerwarteten Ausfall zu minimieren. Um die Wirksamkeit Ihres Notfallwiederherstellungsplans sicherzustellen, müssen regelmäßige Audits, Tests und Aktualisierungen der Verfahren durchgeführt werden.
Support Online verfügt über langjährige Erfahrung in der Implementierung von Disaster Recovery (DR)-Lösungen. In dieser Zeit haben wir Dutzende Tests in verschiedenen Umgebungen durchgeführt und die besten Methoden entwickelt. Heute ermöglichen sie uns die Umsetzung ähnlicher Projekte für Unternehmen, bei denen Sicherheit und Geschäftskontinuität Priorität haben.



